
Why Sharding?
The Good, Bad, and Ugly of Scaling Solutions & why Sharding is the Ultimate Answer


Because my 12 years of experimenting and developing various blockchain architectures have shown me that this is the only design choice that scales with demand and guarantees atomic commitment.
People often ask me, "Why Sharding instead of rollups or similar technologies like Solana or Sui?" After 12 years of working with different blockchain architectures, aiming for a system that scales with demand, I have seen the good, bad, and ugly of all these design choices.
The key question has always been: should we build a system for today's needs or one that can also handle future demands? Based on my experience, sharding is the best design choice to create a system that scales with demand and preserves the composable nature of applications within that system.
So, here’s how I arrived at this conclusion!
Just a quick heads-up before we get started:
I'm planning to make writing a regular thing.
I'll be sharing updates on all things crypto, tech, and some of my random thoughts.
Social media is full of crypto chatter, and this is a way for me to keep my ideas organized.
So, if you're interested, check out my Substack and follow my ramblings:
The Early Days with Bitcoin
Back in 2012, Bitcoin was still in its early stages. People were just starting to play around with it, experimenting with what it could do. I was one of those early adopters, fascinated by the idea of a decentralized currency. Back then, Satoshi Nakamoto's scalability roadmap for Bitcoin seemed adequate.
The idea was simple: as more people started using Bitcoin, the blocks — the batches of transactions added to the blockchain — would get bigger. This would allow more transactions to be processed at once.
At the time, there was a temporary limit on the block size of one megabyte. This was mainly to prevent spam and ensure the network ran smoothly while it was still small. Satoshi thought that as more people used the network and technology got better, the limit could be raised so Bitcoin could process more transactions. This idea relates to Moore's and Nielson's Law (more on that down the line). The mempool, where transactions wait to be processed, would fill up, and miners would pick as many transactions as they could fit into a block. This seemed like a straightforward way to scale Bitcoin.
Playing Around with Bitcoin
When I first started experimenting with Bitcoin, I was curious to see if this scalability plan would suffice with a monolithic design. I spun up a small fork of Bitcoin and created a test network. Using the commodity hardware available in 2012, I managed to get my Bitcoin instance to process around 1,500 transactions per second.
This was quite impressive, comparable to the Visa of the day, but I could see that there were limits. The mempool filled up quickly, and the network had to work hard to keep up.
Some of you might think that Anatoly was the first to base his blockchain's scalability plans on Moore's and Nielsen's Laws.
It was not Anatoly, but Satoshi.
Satoshi's plan relied on the idea that as hardware improved, Bitcoin would naturally scale (does this “thesis” sound familiar ;) ).

Satoshi's vision of Bitcoin's scalability hinged on Moore's Law, which states that computing power will double approximately every two years. If computers kept getting faster and more powerful, they would be able to handle larger blocks of transactions, leading to increased transaction processing capability. This seemed feasible, at least in theory. Moreover, advancements in network capabilities were expected to enable faster block propagation across the network (Nielsen's Law of Internet Bandwidth).

However, this optimistic view missed some critical issues: As block sizes increased, so did the latency in block propagation. Large blocks took longer to distribute across the network, causing significant delays.
Imagine a miner on one side of the network finding a 1 GB block, and another miner on the other side finding another 1 GB block before the first block could fully propagate. This would lead to both blocks competing for confirmation, causing inefficiencies and potential short-term network splits.
This latency issue revealed a significant limitation: larger blocks took longer to propagate, increasing the likelihood of conflicts and orphaned blocks. Miners, in an attempt to mitigate this, would need to be strategic about the number of transactions included in each block. If they included too many, the block might not propagate in time, wasting hash power. This led to a form of self-regulation that was neither efficient nor reliable.
If the growth of Bitcoin remained below the rate of Moore's law, then this latency issue would likely not be a major problem. However, if the growth rate of Bitcoin exceeded that of Moore's law, these latency issues would start to have a real negative effect on the Bitcoin network.
Satoshi also relied on the Simple Payment Verification (SPV) protocol, which allows lightweight clients to verify transactions without downloading the entire blockchain. SPV clients only need the block headers and a small amount of additional verification information relating to their transactions, which remain small regardless of the number of transactions. This seemed viable, but the increasing complexity and volume of transactions posed further challenges.
The Problem with Relying on Moore's and Nielsen's Law for Scalability
For me, it became clear even in 2012 that relying solely on Moore's and Nielsen's Laws for scalability wasn't enough. I realized that transactions would evolve beyond simple payments. While this was speculative at the time, the implications were obvious.
The idea of programmable money, hinted by visionaries like Nick Szabo with smart contracts, would eventually be a game-changer. These distributed ledger networks weren't just about basic transactions anymore; they were about supporting complex decentralized applications and interactions. If networks like Bitcoin were to handle programmable money and decentralized applications, the scalability demands would skyrocket. We're talking tens of thousands of transactions per second (which would sound obvious today), not just a few thousand.
Next to throughput, network limitations were another huge issue. Even with faster internet, the volume of data from large blocks was a nightmare, as the transactions themselves would be larger due to the more complex actions performed. Latency in block propagation would get worse as the network grew.
So relying on Moore's Law and Nielsen's Law for scalability is naive and overly optimistic. This reminds me of how Solana’s founder Anatoly believes it will scale naturally over time. From what I have already seen, Solana's scalability plan is fundamentally flawed; it leans too heavily on Moore's and Nielsen's Law.
Yeah, faster hardware and better connections sound great, but for Solana, the chain hits a limit at around 800-1,000 transactions per second (tps) before problems start. Beyond that point, transactions begin to fail.

Plus, Anatoly’s belief that future hardware advancements alone will handle all this demand is naive. You give bots that capacity, they fill it, and then real users are left out in the cold. And let’s not forget, that Moore’s law isn’t going to help you when you’re already maxed out on the best hardware available.
I digress but, I had to get this off my chest 😀
Exploring Alternative Solutions
Starting off with Block Trees
These realizations concluded with a decision to step away from traditional blockchain architectures, my initial thought was to explore block trees. This was around the time when the concept of directed acyclic graphs (DAGs) was not yet fully mainstream. Fundamentally, a blockchain is a directed acyclic graph with no repeating connections.

So, I wondered, why not expand this idea into a more complex structure, like a tree of blocks instead of a linear chain?
In a block tree, instead of a single chain of blocks, you have multiple branches of blocks that can be processed and undergo consensus simultaneously. This setup would theoretically allow for multiple blocks to be worked on at the same time by different parts of the network. Depending on where you are in the network, some nodes might be working on one set of blocks, while others are working on a different set. The goal was to achieve eventual consistency across these branches, allowing the network to run multiple processes concurrently.
This approach showed some promise initially. It allowed for a form of multi-threading in the blockchain context, potentially increasing throughput. However, similar issues with block propagation emerged as block sizes increased. Larger blocks led to longer propagation times, which in turn caused delays and inefficiencies in the network. There were also complexities in certain cases when attempting to achieve consistency between distant branches (Much in the same way that hampered my DAG research).
This realization prompted me to explore other avenues, leading to the exploration of Directed Acyclic Graphs (DAGs) in the common sense.
Transition to Directed Acyclic Graphs (DAGs)
DAGs seemed like a natural progression from block trees. Traditional DAGs, as we understand them today, like those used in IOTA, offer a way to structure data such that multiple nodes can add new transactions without waiting for previous ones to be confirmed. This sounded like a potential solution to the scalability problems inherent in blockchain networks.

A DAG allows transactions to be appended at any point in the graph, with no strict need for a linear sequence. This flexibility can theoretically result in much higher throughput since multiple transactions can be processed in parallel. However, as I dug deeper into DAGs, it became clear that they presented their own set of challenges.
Challenges with synchronous operations across DAGs
One of the primary issues with DAGs is ensuring synchronous operations across the network. In a blockchain, every node sees the same sequence of blocks, which simplifies consensus. In a DAG, however, nodes can see different versions of the graph. This asynchronicity makes it difficult to achieve a consistent view of the network state.
Anybody can add a transaction to any part of the DAG at any time, leading to potential inconsistencies. If a malicious actor wanted to disrupt the network, they could scatter transactions across the DAG, causing different nodes to see different versions. This discrepancy complicates the process of reaching consensus, as the network must then work to align all nodes to the same state.
Problems with Network Partitions and Message Complexity
Another challenge with DAGs is handling network partitions. When the network splits, reconciling the different parts of the DAG becomes exceedingly complex. Unlike blockchains, where rejoining the network involves simple chain reorganization based on the longest chain rule, DAGs require more intricate merging processes to ensure consistency.
Additionally, the complexity of messages within a DAG increases significantly. Each transaction needs to reference multiple previous transactions to ensure integrity and prevent double-spending. This added complexity means more computational overhead for nodes, which must constantly validate and revalidate these references to maintain the DAG's integrity.
This constant validation is not just a computational burden but also introduces latency into the network. The very advantage of increased throughput is undermined by the need for ongoing integrity checks, making DAGs less efficient than they initially appear.
Channelled Asynchronous State Tree (CAST) and Multi-Threading Execution
In 2016, after exploring the possibilities with block trees and DAGs, I was working on separating the consensus and execution processes in Channelled Asynchronous State Tree (CAST). The idea was to divorce the consensus and execution processes. Execution could happen independently from consensus, which could continue to come to agreement on what should be executed next, and the validity of what has been executed.
CAST allows transactions to be conducted alongside consensus in separate threads, with the results of the execution being reported to the consensus process. The consensus process then determines if all participants agree with the output.

This is very similar to how multi-threaded programs work. Each thread can run independently and only sync up with the main process when needed. This reduces congestion and speeds things up, similar to the methods now being promoted by Aptos and SUI.
So I created execution channels that could dynamically scale - adding or reducing the number of execution threads based on current needs. This flexibility was crucial because it allowed the system to handle varying loads efficiently. For instance, during peak times, more threads could be spun up to manage the increased number of transactions, and during quieter periods, fewer threads were needed, saving on computational resources.
The Consensus Bottleneck of CAST
The consensus process became the main bottleneck in the network. While execution could be spread out and done in parallel, consensus needed to be unified and linear to keep the network's integrity. This single-threaded nature of consensus meant that no matter how fast the execution was, everything had to go through the consensus process, which slowed things down.
The consensus process had to check Merkle hashes and audit paths from various execution channels, using a lot of computational resources and time. Zero Knowledge Proofs (ZKPs) could have maybe helped (despite their drawbacks) but they weren't anywhere near mature enough and VERY expensive.
The main issue was that the consensus process couldn't keep up with the execution channels. Even if transactions were executed in parallel, they still needed to be verified and added to the next block.
This verification process got more demanding and slow as the number of transactions grew. Essentially, the network's ability to execute transactions was faster than its ability to reach consensus on them, creating a bottleneck.
In practical terms, while the execution process could handle thousands of transactions per second, the consensus process struggled to keep up. At best, the system managed about 2,300 transactions per second (tps), which was impressive for 2016 but not enough for the long-term goals of a global, scalable blockchain network. This high transaction rate was achieved by focusing on simple transfers rather than complex smart contracts, which would have added more overhead.
A key insight from this experiment was the advantage of treating execution as an intent rather than processing transactions directly in the consensus process. In practice, this meant that a block would be accepted, and the transactions within it would be executed in a separate thread. Executions which were successful would be committed to the blockchain in a future block. This approach allowed for asynchronous processing, making the system more efficient overall. However, despite these efficiencies, the limited throughput remained a significant drawback.
The Path to Sharding
Just to give you an idea on why I spent years investigating different solutions to scale blockchains: When I was trying to scale blockchains, I wanted it to be as opaque as sharding a database. As a user or developer, I should simply send my query, and the system should handle everything behind the scenes with its clusters and shards, and then return the result. I didn't want users or developers to have any awareness of the complexities behind it.
While I was confident that sharding could get the job done, I didn't want to potentially miss out on the potential for superior alternative methods for scaling. After all, a new technology doesn't always marry nicely with traditional techniques, and blockchain presented a whole new way of doing many things - perhaps even scaling.
Of course, it turns out that sharding is indeed an effective approach for blockchain scaling, but to be sure you have the right solution, you must be thorough in exploring all possibilities.
So, when you look at sharding databases, it's kind of amazing, right?
Just think about it: Google started with a single server and now they're using millions. All that data is sharded, meaning it's split into chunks, cataloged, and managed efficiently. As they add more computing power and resources, they can store more data, and it scales perfectly. This sharding strategy has worked wonders for not just Google, but also Amazon, Facebook, and all those other web2 tech giants.

They all follow this same strategy because it works. Now, if you think this won't work in other scenarios, you're either super naive or just plain arrogant.
The current shiny new "trend" is to just spin up more layers, roll-ups and chains to handle the load. But here’s the catch – each roll-up or layer two solution has its own set of rules and proofs. So, as a developer, I'd have to be aware of all the slight differences between these solutions, the nuances, the behaviours, the primitives types, to have any confidence that my application is reliable and secure.
That’s insane! It’s like trying to speak 400 different languages just to get my application to be composable between all of the applications that are running these L2s and L3s.

And every time you need to send a transaction between roll-ups, you have to go back to the main chain, adding delays and complexity. That’s not scaling, that’s patching holes with duct tape.
I wanted a solution where everything just happened behind the scenes. You'd get a response in a reasonable time while keeping the core values of Bitcoin, like decentralization and permissionlessness. Submit an action, it gets processed. Users shouldn’t have to think about which sidechain or subnet they’re using. They should just send money from point A to point B, and it should work seamlessly.
The Moment I Understood the Need for Linear Scalability
By around 2017, I also realized the need to scale linearly. With networks carrying value, having programmable money, and applications like decentralized marketplaces, we needed a solution that could handle potentially millions of transactions.
Send something in, it gets processed, and you get your result back without worrying about the internal workings. This approach, similar to sharding databases, was the only viable path for scaling.

So, the real question was, how do we get this kind of linear scale from sharding?
Traditionally, the way systems handle sharding is pretty crude. An admin figures out the specs, sets up 10 shards and 10 clusters or whatever, and if things need to change, it's a logistical nightmare. You have to scale up, move things around, and keep everything synchronized.

For a company like Google, there is literally an army of people doing this work around the clock - maintaining the system, resolving issues such as hard drive or server failures, keeping everything running smoothly. It's a 24/7 job that requires immense resources and manpower to pull off at their scale.
While some aspects can be automated, the sheer complexity of this process cannot be overstated - it's a full-time job for entire teams of highly skilled professionals and a resource-intensive aspect of modern data management.
In a decentralized system, which could have tens or hundreds of thousands of machines, there's no single admin to reconfigure everything. So, how do you manage that? How do you do it autonomously, without permission, in a decentralized way? That's the real challenge with sharding – making the network adjust itself to the load and move data around automatically.
I realized the key was to chop up the state and distribute it uniformly across the network with a new and novel mechanism to manage it. Multiple consensus processes operating collaboratively could maintain the state and finally resolve the consensus bottleneck that had plagued the previous designs.
That's where the innovation comes in – the sharding model and the state model.
State Sharding: The Best Path to True Linear Scalability
Once I’d concluded after many years of grinding that sharding is the only viable path, I was deep in the weeds with this sharding stuff, and let me tell you, I’ve seen a lot of dead-end ideas.
Beacon Chain? More Like Bottleneck Chain

Beacon Chain was one of the first things I tossed aside. Sure, it looks good on paper, but in reality, it’s just another layer of complexity that slows everything down.
Think about it: every time you need to reshuffle the network or add more shards, you have to interact with this Beacon Chain. It’s supposed to coordinate validators and keep everyone in sync, but it also adds a massive bottleneck. You’re constantly interacting with this central chain, and that kills any real chance of linear scalability because eventually it will hit a throughput limit. I wanted a system that could handle changes autonomously, without needing this middleman to orchestrate every move.
With a Beacon chain, essentially all validators are involved in coming to a decision on actions which fall within its scope. That being the case, you really don’t need a Beacon chain at all! Simply allow all validators to act as a single set for those actions, come to an agreement, and record the result in such a way that all validators have auditable proof of the decision.
Beacon Chain was just a non-starter for me. It’s like trying to run a race while dragging a ball and chain behind you.
I also considered the typical approach of starting with a single chain and sharding it as the network grows (Dynamic Sharding). However, this creates a lot of overhead - every time you add a shard, the entire state topology has to be reconfigured. It's complicated, compute intense and limits scalability.
Intra-validator Sharding Will Hit a Wall as well
Next up, Sui and their intra-validator sharding. It’s not exactly sharding but they have this idea where a primary, network facing validator acts as a load balancer and orchestrator for a bunch of secondary validators behind it.
Sounds clever, right?
Wrong. It works until you hit resource saturation on the primaries. There’s only so much data a single validator can ingest and process before it chokes. When you then try to alleviate the problem, and scale by adding more primary validators, you end up with an increase of message complexity, authentication complexity and network latency.
Instead of solving the problem, this approach pushes it elsewhere and kicks a can down the road a bit. Eventually there are such a quantity of primary validators that the consensus mechanism becomes inefficient and you’re experiencing diminishing returns unless you get hardcore and modify the consensus protocol itself.
Sui’s approach just doesn’t hold up when you look at the real-world demands of scaling a network.
Why State Sharding is the Clear Winner
So after excluding all these options, I mandated some non-negotiable capabilities which must be present along with linear scale, and state sharding was the core enabler within the design.
In a state-sharded ledger, each shard maintains only a portion of the full state. Transactions that involve states from different shards require cross-shard communication to update the state in all relevant shards atomically. This allows the blockchain to process transactions in parallel across multiple shards, only concerning themselves with transactions which modify state for which they are responsible, significantly increasing throughput.
With a good state sharding model, the state can be uniformly distributed around the network, decreasing the likelihood of hotspots, and increasing efficiency across the board.. The numerous consensus processes can operate near their maximum throughput potential for prolonged periods of time with the agreed state transitions forming a directed acyclic graph (DAG) that references all necessary consensus processes and their quorum outputs.
Why hardware agnosticism matters
The network needs to be hardware-agnostic. If your network can run on almost any hardware, it means more people can participate. We might expect everyone to operate top-tier 8-core machines, but guess what? If they turn up with Raspberry Pi 3s, it’s still fine. We’ll just increase the number of validator sets.
If we need to handle 100,000 transactions per second with Raspberry Pi 3s, we’ll use 300 validator sets instead of 100 for example.
With this approach, you’d actually get better decentralization because you need more validators – more actors in the system. The network doesn’t care about the hardware used, just that there is enough of it to meet the demand..
I’m not saying this as something that comes in the future either, I do all my tests with the lowest reasonable spec – a 4-core, 8GB machine with a SATA SSD.

This ensures there’s no barrier to entry due to machine cost. If we need more validators to handle the load, we get more validators. Simple.
That’s the beauty of State Sharding. It doesn’t matter if each validator is handling a smaller fraction of state, and therefore transactions. As long as we maintain liveness, safety, and decentralization, we’re good.
Why Atomic Commitment in Sharding is important
Then, there's the atomic commitment aspect. You want a network where all data & state can interact seamlessly. Atomic commitment ensures that transactions across shards are either fully completed or not at all. Without atomicity, you risk “hanging state” if a transaction failed halfway through which then introduces complex, messy rollback procedures to clean up all the shards to their original state. Imagine shard A does something to shard B, but shard B fails. Shard A then needs to undo its action. If something happened in the meantime, shard A might not be able to roll back without causing issues. This is a real headache for developers to deal with, along with potential, disastrous safety issues!
But with atomic commitment, if any part of the transaction fails, everything aborts cleanly, and there’s no extra work to untangle those hanging state changes.. It's clean, it's efficient, and it prevents all those rollback headaches. No one else has this figured out how to do this cleanly, and state sharding is part of the solution..
This setup is rock solid for a wide range of use cases. Sure, some specific use cases might do better with L2 solutions or brute force compute such as Solana, but that's just a small fraction. I was aiming to build a network that can grow and adapt, capturing 99% of the use cases and leaving no stone unturned.
After Years of Trial and Error, the Network Finally Takes Shape
Armed with knowledge and learning from all the previous research, I had a clear path forward. , First, I decided to take a radically different sharding approach by pre-sharding the ledger into 2^256 shards from day one. This way, the shard space never needs to change as the network grows, the state never needs to move, and instead validators are mapped onto the shard space.
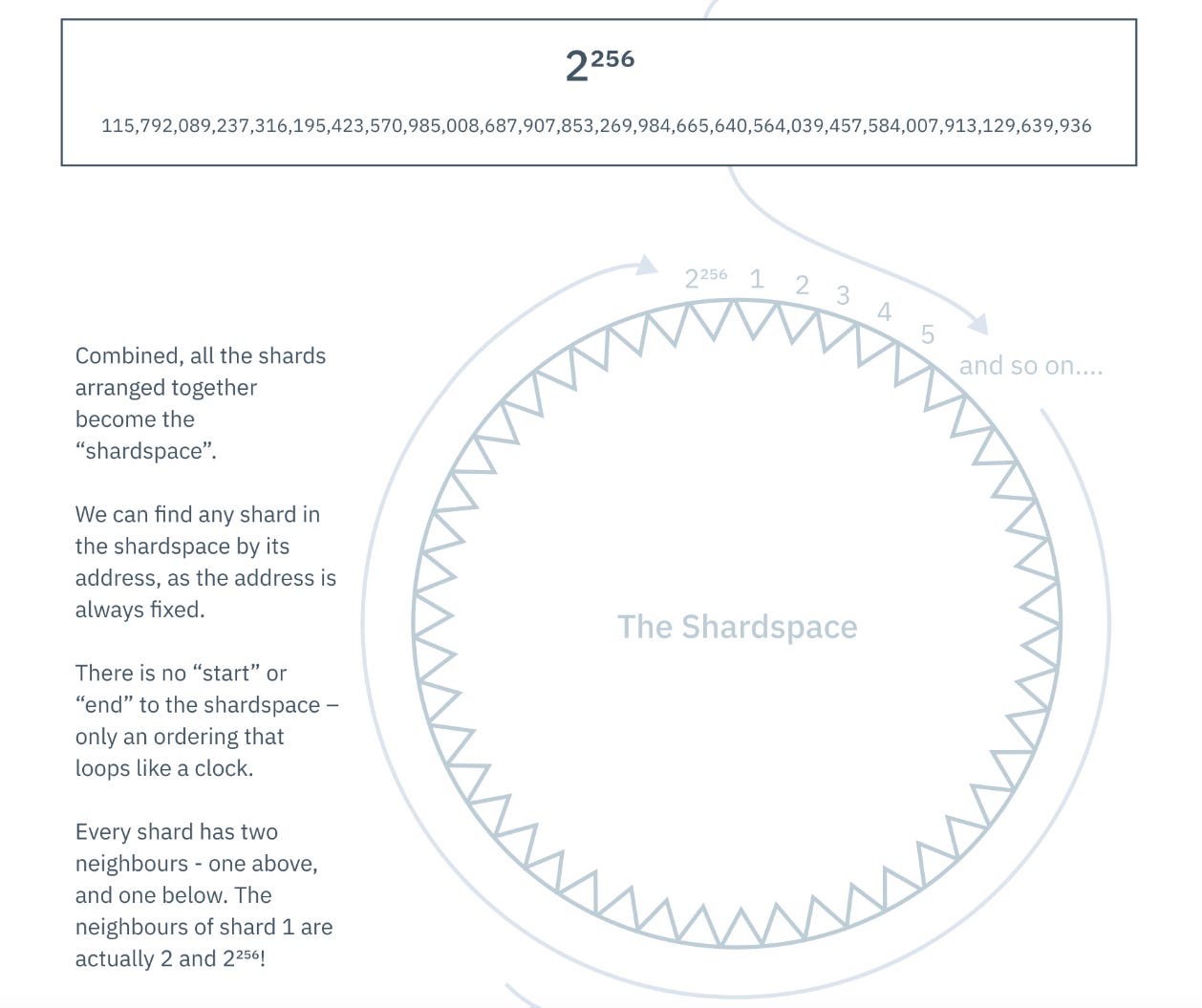
Through the innovative design of how we assign data to shards deterministically using SHA-256, we can ensure transactions always touch a minimal number of shards, and crucially, all validators in the network know which set of validators are responsible for any given state at any time. This has enormous implications in the efficiency and reduced complexity required for cross-shard communications
But pre-sharding alone doesn't solve the atomic commitment problem. This is where there is another key insight: what if we could temporarily combine (Braid) only the necessary shards for a specific transaction, let them reach consensus, and then separate (Unbraid) them again?
This was the genesis of our Cerberus consensus protocol.

In Cerberus, each shard is managed by a set of validator nodes. For each transaction, we create an ephemeral validator set comprised of just the validators managing the required shards. They operate a Byzantine Fault Tolerant consensus on that transaction, braiding the shards together. Once it's committed, the shards are unbraided and can process the next transactions independently. This allows practically unlimited parallelization.
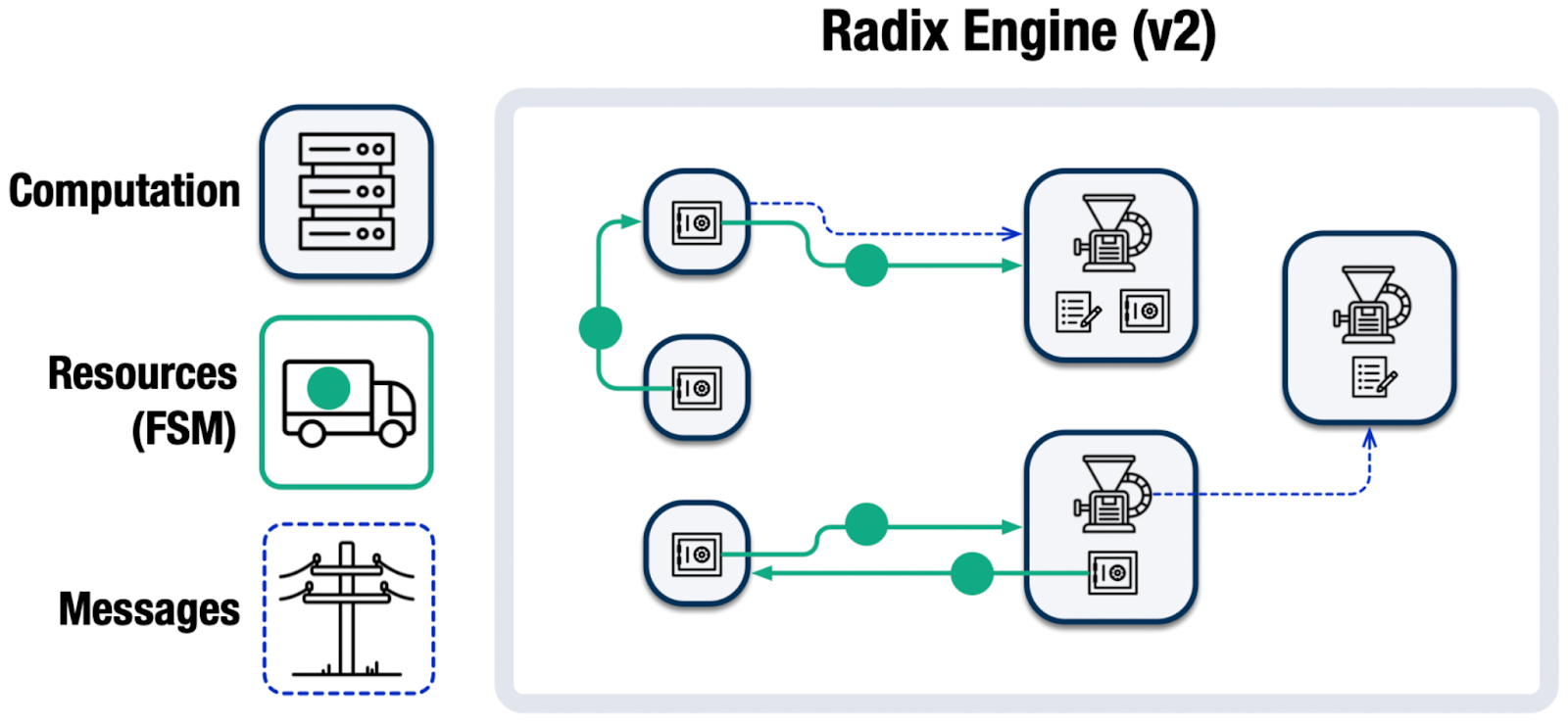
The last piece of the puzzle was our application layer, the Radix Engine. We designed it from the ground up to translate application logic into discrete finite state machines that map cleanly to the sharded data structure.
Resources and components each get their own shard, allowing them to be updated in parallel.
Final Thoughts

It's been a long journey, filled with many dead ends and false starts. However, I firmly believe that without taking this path, I would never have figured out a solution that could finally work. There were times, especially when going back to the drawing board, when I thought I should have just launched a protocol with one of the more than ‘good enough’ solutions and it would have commanded significant market share.
But that's not the point. The challenge I have personally taken on is to finally deliver on the promise of Distributed Ledger Technology (DLT) at a global scale. This is where my team's efforts are focused now. I can't wait to see what kind of applications and innovations this innovative technology we have at Radix will unlock!
Hey, if you enjoyed these insights and want to read more articles like this, subscribe to my blog.
I’ll be sharing regular updates on all things crypto, tech, and my random thoughts.
It’s hard to compete with all the crypto noise on social media, and this helps me organize my thoughts better.
So, check out my Substack and follow my ramblings:
Excellent article!
We are living in a time of darkness and paradox in the crypto market. We want to move into the mainstream, but we invest in a system that does not meet the minimum requirements of a critical security system and that delegates everything. As if Fiat currency were not enough, we still have the Mainstream Paradox to break.
But we, the Fundamento Cripto team, will always support Radix, especially here in Brazil, and we truly want to change the course of history when we think about individual sovereignty and finances. Radix is part of our daily lives, because in every study we do of other projects, we have Radix as a benchmark. Radix always stands out by a long way from other projects for many reasons, many of which are in this article.
We are still a voice that is rarely heard, but we are in no hurry, because we know that a disruptive technology comes with a change in the culture of its members, and this takes time.
We are still few and we will not give up, because we already understand that Radix is inevitable!
Forward Radix, always!
This was the best explanation I have heard yet. Great article Dan. Thank you for making it readable for a novice like me.